Flume log appender
The Flume log appender encapsulates the received logs into Flume events and sends them to external Flume sources using Avro RPC.
Create Flume log appender
To create a Flume log appender for your application using the Administration UI:
-
Log in to the Administration UI page as a tenant developer.
-
Click Applications and open the Log appenders page of your application. Click Add log appender.
-
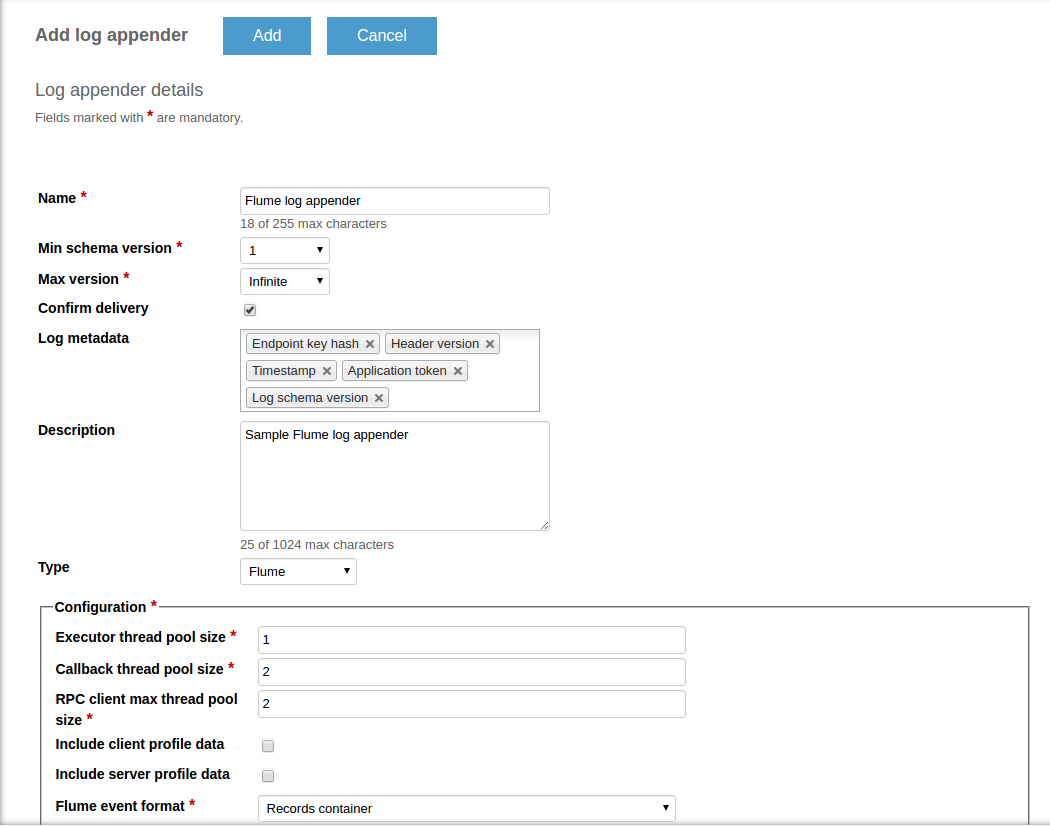
On the Log appender details page, enter the necessary information and set the Type field to Flume.
-
Fill in the Configuration section for your log appender. See Configure log appender.
-
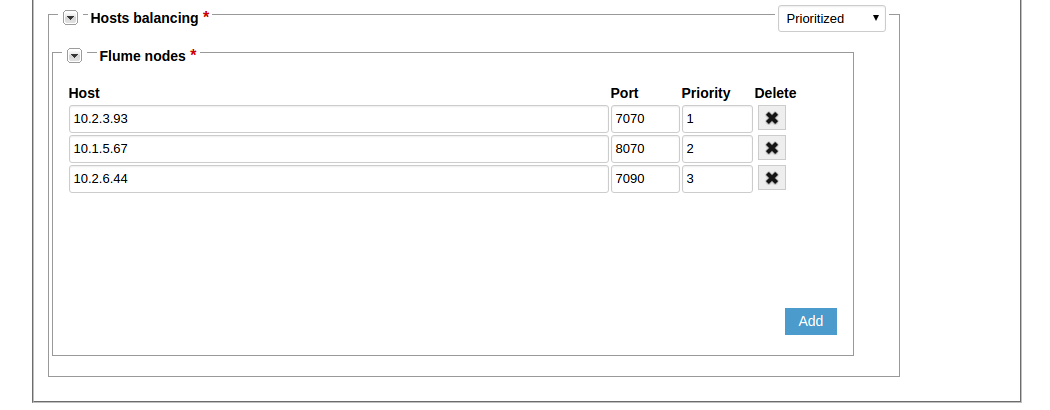
Configure host balancing. Flume log appenders can have either prioritized or round-robin host balancing.
For the prioritized host balancing, add the number of hosts which is equal to the number of Flume nodes. For every host, enter the host address, port and priority. The highest priority value is 1. When choosing a server to save the logs to, an endpoint will send requests to the servers starting from the highest priority server.
For round-robin host balancing, add the number of hosts which is equal to the number of Flume nodes. For every host, enter the host address and port. When choosing a server to save the logs to, an endpoint will send requests to the servers according to the round-robin algorithm.
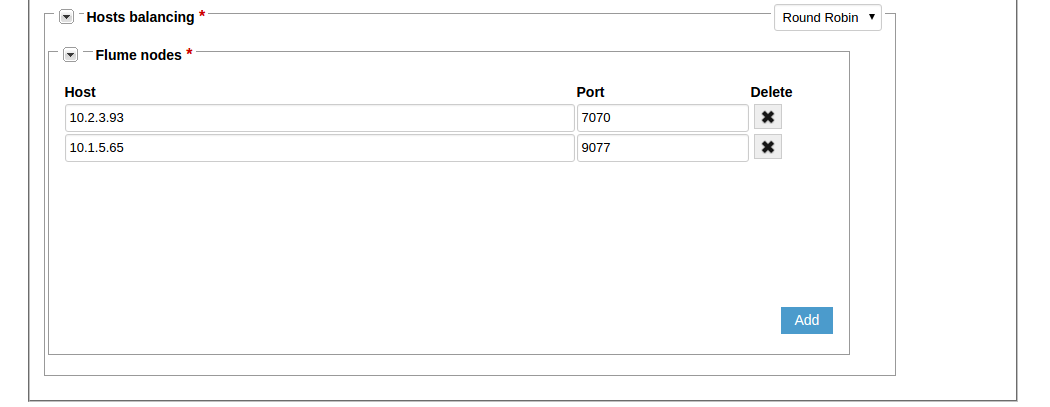
When you are done setting up the host balancing, click the Add button to add the new log appender.
Alternatively, you can use the server REST API to create or edit your log appender.
The following example illustrates how to create an instance of Flume log appender using the server REST API.
curl -v -S -u devuser:devuser123 -X POST -H 'Content-Type: application/json' -d @flumeLogAppender.json "http://localhost:8080/kaaAdmin/rest/api/logAppender" | python -mjson.tool
where file flumeLogAppender.json contains the following data.
{
"pluginClassName":"org.kaaproject.kaa.server.appenders.flume.appender.FlumeLogAppender",
"pluginTypeName":"Flume",
"applicationId":"5",
"applicationToken":"82635305199158071549",
"name":"Sample Flume log appender",
"description":"Sample Flume log appender",
"headerStructure":[
"KEYHASH",
"VERSION",
"TIMESTAMP",
"TOKEN",
"LSVERSION"
],
"maxLogSchemaVersion":2147483647,
"minLogSchemaVersion":1,
"tenantId":"1",
"jsonConfiguration":"{\"executorThreadPoolSize\":1,\"callbackThreadPoolSize\":2,\"clientsThreadPoolSize\":2,\"includeClientProfile\":{\"boolean\":false},\"includeServerProfile\":{\"boolean\":false},\"flumeEventFormat\":\"RECORDS_CONTAINER\",\"hostsBalancing\":{\"org.kaaproject.kaa.server.appenders.flume.config.gen.PrioritizedFlumeNodes\":{\"flumeNodes\":[{\"host\":\"10.2.3.93\",\"port\":7070,\"priority\":1},{\"host\":\"10.1.5.67\",\"port\":8070,\"priority\":2},{\"host\":\"10.2.6.44\",\"port\":7090,\"priority\":3}]}}}"
}
Below is an example result.
{
"applicationId": "5",
"applicationToken": "82635305199158071549",
"confirmDelivery": true,
"createdTime": 1466496979110,
"createdUsername": "devuser",
"description": "Sample Flume log appender",
"headerStructure": [
"KEYHASH",
"VERSION",
"TIMESTAMP",
"TOKEN",
"LSVERSION"
],
"id": "131074",
"jsonConfiguration": "{\"executorThreadPoolSize\":1,\"callbackThreadPoolSize\":2,\"clientsThreadPoolSize\":2,\"includeClientProfile\":{\"boolean\":false},\"includeServerProfile\":{\"boolean\":false},\"flumeEventFormat\":\"RECORDS_CONTAINER\",\"hostsBalancing\":{\"org.kaaproject.kaa.server.appenders.flume.config.gen.PrioritizedFlumeNodes\":{\"flumeNodes\":[{\"host\":\"10.2.3.93\",\"port\":7070,\"priority\":1},{\"host\":\"10.1.5.67\",\"port\":8070,\"priority\":2},{\"host\":\"10.2.6.44\",\"port\":7090,\"priority\":3}]}}}",
"maxLogSchemaVersion": 2147483647,
"minLogSchemaVersion": 1,
"name": "Sample Flume log appender",
"pluginClassName": "org.kaaproject.kaa.server.appenders.flume.appender.FlumeLogAppender",
"pluginTypeName": "Flume",
"tenantId": "1"
}
Configure log appender
The configuration of Flume log appender must match this Avro schema.
Use the following parameters to configure your Flume log appender.
| Name | Description |
|---|---|
executorThreadPoolSize |
Executor thread pool size. |
callbackThreadPoolSize |
Callback thread pool size. |
clientsThreadPoolSize |
Maximum size of RPC client thread pool. |
includeClientProfile |
Client-side endpoint profile data (boolean value). |
includeServerProfile |
Server-side endpoint profile data (boolean value). |
flumeEventFormat |
Records container or Generic. |
hostsBalancing |
Prioritized or round-robin. |
FlumeNodes |
Flume nodes. |
Below is an example configuration that matches the mentioned Avro schema.
{
"executorThreadPoolSize":1,
"callbackThreadPoolSize":2,
"clientsThreadPoolSize":2,
"includeClientProfile":{
"boolean":true
},
"includeServerProfile":{
"boolean":true
},
"flumeEventFormat":"RECORDS_CONTAINER",
"hostsBalancing":{
"org.kaaproject.kaa.server.appenders.flume.config.gen.FlumeNodes":{
"flumeNodes":[
{
"host":"localhost",
"port":7070
},
{
"host":"notlocalhost",
"port":7070
}
]
}
}
}
Formats
The Flume log appender can be configured to generate events using either Records container or Generic format.
Records container
When the Records container format is used, the log records are serialized by the following RecordData schema as a binary Avro file and stored in the Flume event raw body.
The RecordData schema has the following four fields:
recordHeader– stores a set of log metadata fields.eventRecords– stores an array of raw records. Each element of the array is a log record in the Avro binary format serialized by the log schema.schemaVersionandapplicationToken– are used as parameters of the server REST API call to Kaa to obtain the logs Avro schema foreventRecordsand enable parsing of the binary data.
See example below.
{
"type":"record",
"name":"RecordData",
"namespace":"org.kaaproject.kaa.server.common.log.shared.avro.gen",
"fields":[
{
"name":"recordHeader",
"type":[
{
"type":"record",
"name":"RecordHeader",
"namespace":"org.kaaproject.kaa.server.common.log.shared.avro.gen",
"fields":[
{
"name":"endpointKeyHash",
"type":[
{
"type":"string"
},
"null"
]
},
{
"name":"applicationToken",
"type":[
{
"type":"string"
},
"null"
]
},
{
"name":"headerVersion",
"type":[
{
"type":"int"
},
"null"
]
},
{
"name":"timestamp",
"type":[
{
"type":"long"
},
"null"
]
},
{
"name":"logSchemaVersion",
"type":[
{
"type":"int"
},
"null"
]
}
]
},
"null"
]
},
{
"name":"schemaVersion",
"type":"int"
},
{
"name":"applicationToken",
"type":"string"
},
{
"name":"eventRecords",
"type":{
"type":"array",
"items":{
"name":"RecordEvent",
"namespace":"org.kaaproject.kaa.server.common.log.shared.avro.gen",
"type":"bytes"
}
}
},
{
"name":"clientProfileBody",
"type":[
{
"type":"string"
},
"null"
]
},
{
"name":"clientSchemaId",
"type":[
{
"type":"string"
},
"null"
]
},
{
"name":"serverProfileBody",
"type":[
{
"type":"string"
},
"null"
]
},
{
"name":"serverSchemaId",
"type":[
{
"type":"string"
},
"null"
]
}
]
}
Generic
When the Generic format is used, every log record is represented as a separate Flume event.
The Flume event body contains a log record serialized by the log schema in the Avro binary format.
The Flume event header contains the log schema definition mapped by the flume.avro.schema.literal key.
In addition, Kaa provides the following two extended Flume agents that can be used together with the Flume log appender.
- Kaa flume source – a Flume agent with the extension to the standard Flume NG Avro Sink that includes additional features and performance improvements. The Kaa flume source receives data from the Flume log appender and delivers it to an external Avro Source located in a Hadoop cluster.
- Kaa flume sink – a Flume agent with the extension to the standard Flume NG HDFS Sink that includes additional features. The Kaa flume sink detects the logs data schema and stores the log data into HDFS as Avro Sequence files using the Avro schema below.
{
"type":"record",
"name":"RecordWrapper",
"namespace":"org.kaaproject.kaa.log",
"fields":[
{
"name":"recordHeader",
"type":[
{
"type":"record",
"name":"RecordHeader",
"namespace":"org.kaaproject.kaa.server.common.log.shared.avro.gen",
"fields":[
{
"name":"endpointKeyHash",
"type":[
{
"type":"string"
},
"null"
]
},
{
"name":"applicationToken",
"type":[
{
"type":"string"
},
"null"
]
},
{
"name":"headerVersion",
"type":[
{
"type":"int"
},
"null"
]
},
{
"name":"timestamp",
"type":[
{
"type":"long"
},
"null"
]
}
]
},
"null"
]
},
{
"name":"recordData",
"type":[
${
record_data_schema
},
"null"
]
}
]
}
${record_data_schema} is a variable substituted at run time by Kaa HDFS Sink with the Avro schema of the actual logs.
This Avro schema is obtained trough the server REST API call to Kaa.
Playing with Flume log appender
The example below uses the Data collection demo from Kaa Sandbox.
To play around with the log appender:
-
Open the Data collection demo from Kaa Sandbox, follow the application installation instructions, and run the application.
-
Create a Flume log appender as described above.
-
Your running Data collection demo application will display the output similar to the example below.
Data collection demo started Received new sample period: 1 Sampled temperature 28 1474622330 Sampled temperature 31 1474622331 Sampled temperature 32 1474622332 Sampled temperature 30 1474622333 Sampled temperature 28 1474622334 ...
The logs are stored within the HDFS path defined during Kaa Flume sink setup.
If you don’t get the desired output or experience other problems, see Troubleshooting.