Architecture overview
This section discusses fundamental concepts behind Kaa architecture and logical design.
Kaa IoT platform consists of Kaa server, Kaa extensions, and the endpoint SDKs.
- Kaa server is the back-end part of the platform. It is used to manage tenants, applications, users and devices. Kaa server exposes integration interfaces and offers administrative capabilities.
-
Kaa extensions are independent software modules that improve the platform functionality.
NOTE: In this version of the documentation, you will notice that some extensions are actually managed within the core of the platform. Those are planned to be fully decoupled in future Kaa releases.
- Endpoint SDK is a library that provides client-side APIs for various Kaa platform features and handles communication, data marshalling, persistence, etc. Kaa SDKs are designed to facilitate the creation of client applications to be run on various connected devices. However, client applications that do not use Kaa endpoint SDK are also possible. There are several endpoint SDK types available in different programming languages.
Kaa cluster
Kaa server nodes use Apache ZooKeeper to coordinate services. Interconnected nodes make up a Kaa cluster associated with a particular Kaa instance. Kaa cluster requires NoSQL and SQL database instances to store endpoint data and metadata, accordingly.
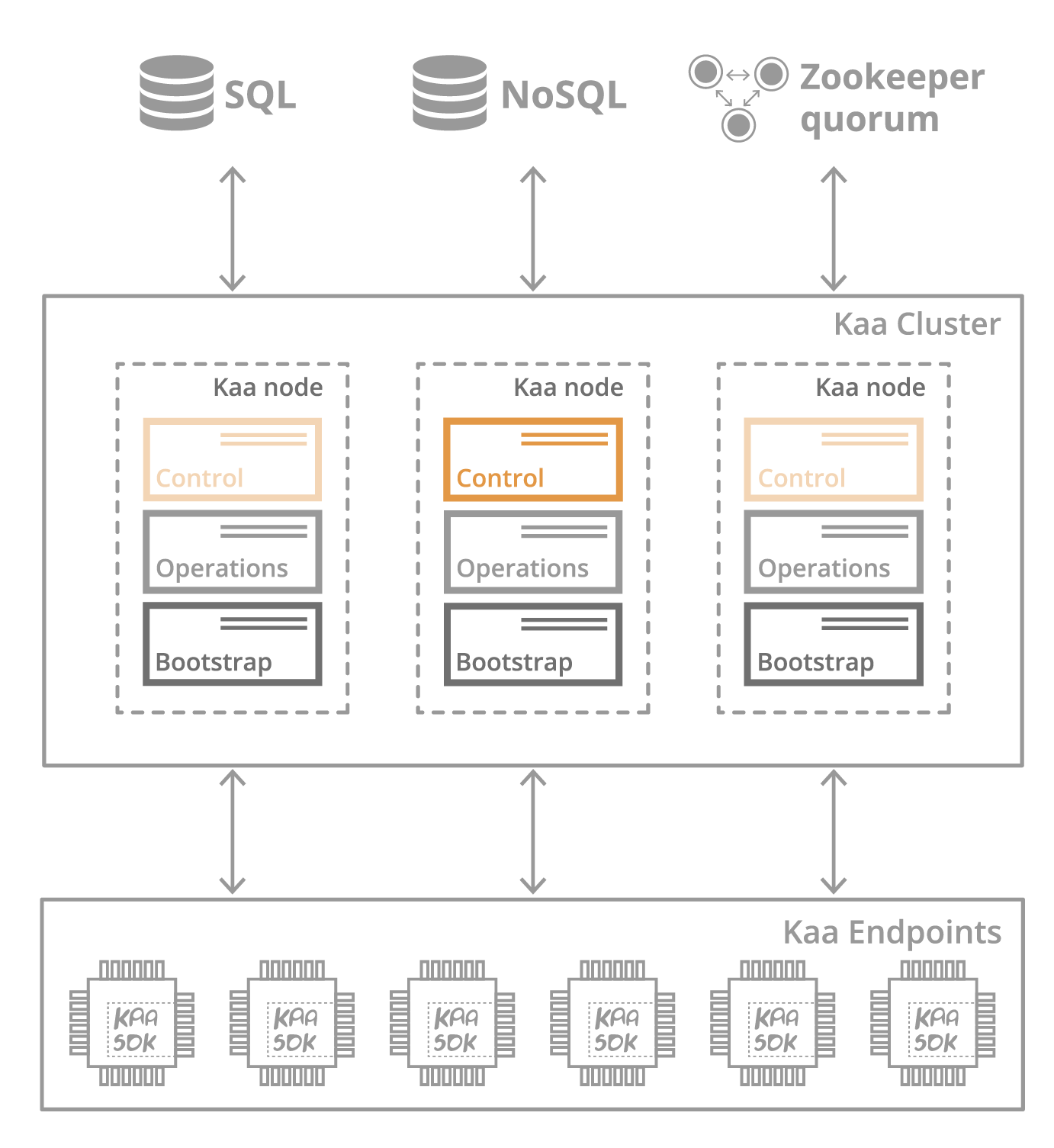
Kaa nodes in a cluster run a combination of Control, Operations, and Bootstrap services.
Control service
Kaa Control service manages overall system data, processes API calls from the web UI and external integrated systems, and sends notifications to Operations services. Control service maintains an up-to-date list of available Operations services by continuously receiving this information from ZooKeeper. Additionally, Control service runs embedded Administrative web UI component that uses Control service APIs to provide platform users with a convenient web-based interface for managing tenants, user accounts, applications, application data, etc.
To support high availability (HA), a Kaa cluster must include at least two nodes with Control service enabled. In HA mode, one of the Control services acts as active and the other(s) function in standby mode. In case of the active Control service failure, ZooKeeper notifies one of the standby Control service and promotes it to the active Control service.
Operations service
The primary role of the Operations service is to communicate with multiple endpoints concurrently. Operations services process the endpoint requests and sends data to them.
For the purpose of horizontal scaling, you can set up a Kaa cluster with Operations service enabled for every node. In this case, all instances of Operations service will function concurrently. In case of an Operations service outage, previously connected endpoints switch to other available Operations services automatically. Kaa server can re-balance the load at run time, thus effectively routing endpoints to the less loaded nodes in the cluster.
Bootstrap service
Kaa Bootstrap service sends the information to the endpoints about Operations services connection parameters. Depending on the configured protocol stack, connection parameters may include IP address, TCP port, security credentials, etc. Kaa SDKs contain a pre-generated list of Bootstrap services available in the Kaa cluster that was used to generate the SDK library. Endpoints query Bootstrap services from this list to retrieve connection parameters for the currently available Operations services. Bootstrap services maintain their lists of available Operations services by coordinating with ZooKeeper.
Third-party components
Zookeeper
Apache ZooKeeper enables highly reliable distributed coordination of Kaa cluster nodes. Each Kaa node continuously pushes information about connection parameters, enabled services and the corresponding services load. Other Kaa nodes use this information to get the list of their siblings and communicate with them. Active Control service uses the information about available Bootstrap services and their connection parameters during the SDK generation.
SQL database
SQL database instance is used to store tenants, applications, endpoint groups and other metadata that does not grow as the number of endpoints increases.
High availability of a Kaa cluster is achieved by deploying the SQL database in HA mode. Kaa officially supports MariaDB and PostgreSQL as the embedded SQL databases at the moment.
NoSQL database
NoSQL database instance is used to store endpoint-related data that grows linearly as the number of endpoints increases.
NoSQL database nodes can be co-located with Kaa nodes on the same physical or virtual machines, and should be deployed in HA mode for the overall high availability of the system. Kaa officially supports Apache Cassandra and MongoDB as the embedded NoSQL database at the moment.
Internode communications
Kaa services use Apache Thirft to communicate across processes and nodes. Each service obtains metadata about its siblings using Apache ZooKeeper. This metadata contains information about the Thrift host and port.
High availability and scalability
Kaa cluster scales horizontally and linearly; there is no single point of failure in Kaa cluster architecture. Kaa Operations and Bootstrap services are identical and function in active-active HA mode. One of the cluster nodes contains an active Control service. In case that node fails, a standby Control service in another node is promoted to become active. High availability of Kaa Cluster also depends on HA of SQL and NoSQL databases.
Active load balancing
Kaa SDK chooses Bootstrap and Operations service instances pseudo-randomly during session initiation. Two load balancing methods are used depending on the on the originator of requests to the Kaa cluster: Kaa endpoint SDK or REST API.
Endpoint SDK requests
Kaa SDK chooses the Bootstrap and the Operations service instances pseudo-randomly during the session initiation. However, if the cluster is heavily loaded, random distribution of endpoints may not be efficient. Also, when a new node joins the cluster, it is required to re-balance the load in the updated topology for optimal performance.
Kaa server uses the active load balancing approach to instruct some of the endpoints to reconnect to a different Operations service thus equalizing the load across the nodes. The algorithm takes the server load data (connected endpoints count, load average, etc.) published by Kaa nodes as an input, and periodically recalculates the weight values of each node. Then, the overloaded nodes are instructed to redirect to a different node some of endpoints that request connection.
A similar approach can be used to take some load off a node by means of a scheduled service, or to gradually migrate the cluster across the physical or virtual machines. To do that, you need to set up a custom load balancing strategy by implementing the Rebalancer interface. See the default implementation for more details.
REST API requests
For REST API load balancing, you can use the existing HTTP(s) load balancing solutions with sticky session support, such as Nginx, AWS Elastic Load balancing, Google Cloud LB.
Kaa instance
Kaa instance (Kaa deployment) is a particular installation of the Kaa platform, either as a single node, or a clustered deployment.
An application in Kaa defines a set of data models, types of communication between the endpoints and Kaa server, and processing rules. Kaa applications are not specific to the target platform, operating system, or the client software implementation. For example, two firmware implementations for a pressure sensor will differ between Arduino and STM32 platforms, yet will be considered the same application in Kaa as long as they report identically structured telemetry data.
Kaa platform is multi-tenant. A single Kaa instance can support multiple independent business entities. Applications belong to tenants, while endpoints register within applications (see the picture below).
An endpoint (EP) is an abstraction that represents a separately managed entity within a Kaa deployment. Practically speaking, an endpoint is a specific Kaa client registered (or waiting to be registered) within a Kaa instance. Depending on the use case, different level physical entities can be considered endpoints. In an industrial setting, a single air quality sensor can represent an individual endpoint, while in a fleet tracking application, a truck (despite carrying on board multiple sensors that report data) may be a more appropriate entity to be declared as an endpoint.
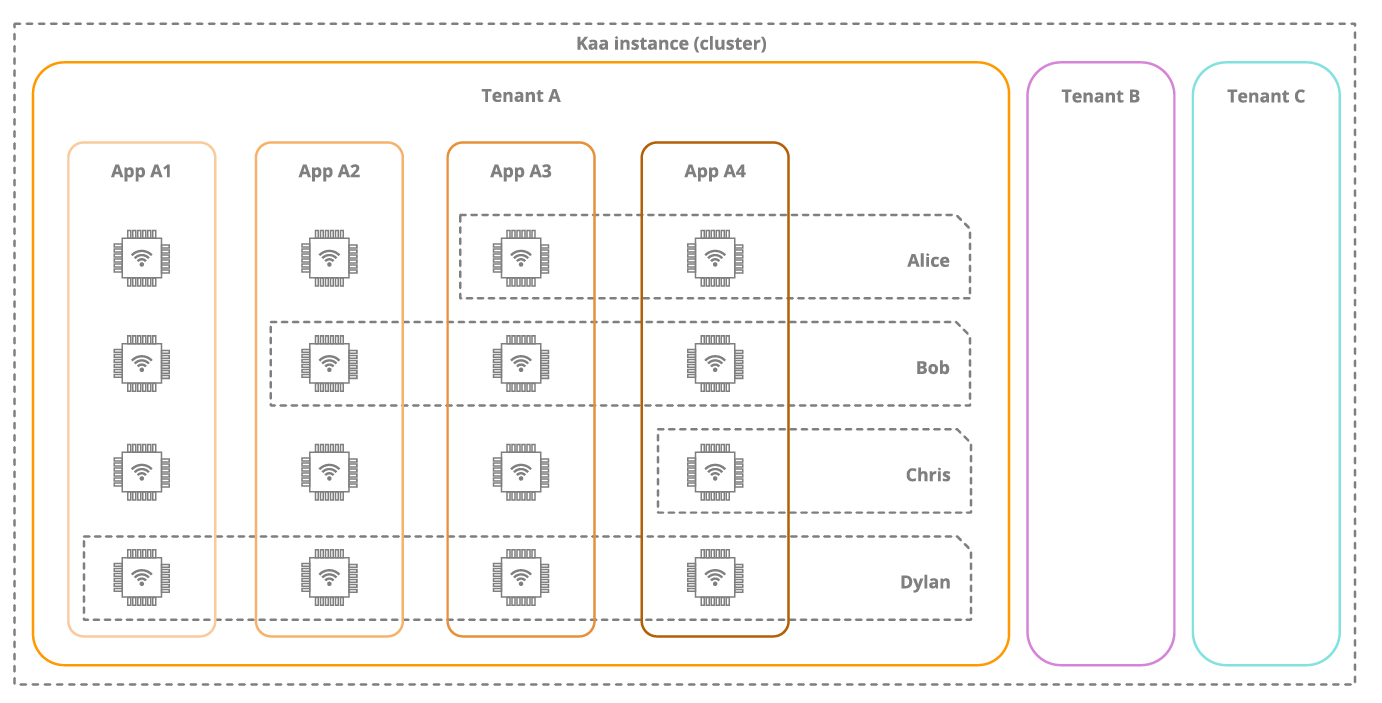
To distinguish endpoints by different properties, rather than use one ID, Kaa uses endpoint profiles.
Endpoint profile is a custom structured data set that describes characteristics of a specific endpoint within an application. Every endpoint profile comprises the client-side, server-side, and system parts. Initial values for the client-side part are specified by the the client developer using data schemas for the endpoint SDK. Then, the client-side endpoint profile is generated during registration of a new endpoint. The server-side and system parts of the endpoint profile data are managed by the Kaa server.
See also Endpoint profiles.
Profile data is used to attribute endpoints to endpoint groups — independently managed entities defined by profile filters. Those endpoints whose profiles match the profile filters of a specific endpoint group automatically become members of this group. An endpoint can be a member of unlimited number of groups at the same time.
Endpoints can also be associated with owners. Depending on the application, owners can be persons, groups of people, or organizations.
Further reading
Use the following guides and references to learn more about Kaa features.
| Guide | What it is for |
|---|---|
| Key platform features | Learn about Kaa key features, such as endpoint profiling, data collection, configuration management, events, notifications, and others. |
| Installation guide | Install and configure Kaa platform on a single Linux node or in a cluster environment. |
| Contribute to Kaa | Learn how to contribute to Kaa project and which code/documentation style conventions we adhere to. |